构建 Claude Code 的经验:我们如何使用 skills
Anthropic 的 Claude Code 团队总结了内部使用 skills 的九类方式,以及编写、分发和维护 skills 的实践经验。
构建 Claude Code 的经验:我们如何使用 skills
Anthropic 的 Claude Code 团队总结了内部使用 skills 的九类方式,以及编写、分发和维护 skills 的实践经验。
Skills 已经成为 Claude Code 中使用最广泛的扩展点之一。它们灵活、易于创建,也易于分发。
但这种灵活性也让人很难判断什么做法最有效。哪些类型的 skills 值得创建?应该如何组织一个 skill?什么时候该把它们分享给其他人?
在 Anthropic,我们已经在 Claude Code 中大量使用 skills,目前有数百个 skills 正在活跃使用。下面是我们总结出的经验:如何用 skills 加速开发。
什么是 skills?
Skills 是由指令、脚本和资源组成的文件夹,Agent 可以发现并使用它们,从而更准确、更高效地完成任务。本文假定你已经熟悉 skills 的基础知识;如果你是新手,请先学习我们的 Skilljar 上的 Agent skills 入门课程。
关于 skills,一个常见误解是它们“只是 markdown 文件”。实际上,它们是文件夹,可以包含脚本、资产、数据等,Agent 可以发现、探索并操作这些内容。
在 Claude Code 中,skills 也有多种配置选项,包括注册动态 hooks。
我们发现,Claude Code 中一些最有效的 skills,会有效利用这些配置选项和文件夹结构。
skills 的类型
在整理完 Anthropic 内部所有 skills 后,我们注意到它们大致聚成九类。最好的 skills 会清晰地归入其中一类;那些试图做太多事情的 skills 往往横跨好几类,反而让 Agent 困惑。这不是一份最终定论式的清单,但它是一个有用的框架,可以帮助你发现自己 skills 库中的空白。

Claude Code 团队对我们的内部 skills 进行了分类,发现它们可以归入九个不同类别。
1. 库和 API 参考
这类 skills 会说明如何正确使用某个库、CLI 或 SDK。它们既可以面向内部库,也可以面向 Claude Code 有时难以处理的常用库。这些 skills 通常会包含一个参考代码片段文件夹,以及一份 Claude 在编写脚本时需要避开的 gotchas 清单。
示例包括:
-
billing-lib — 你的内部计费库:边界情况、坑点等等。
-
internal-platform-cli — 你的内部 CLI 封装器的每个子命令,并附上何时使用它们的示例。
-
sandbox-proxy — 为开发工作配置你所在组织的出口网关:哪些主机可访问,如何调试 "connection refused" 错误,如何添加 allowlist 条目。
2. 产品验证
这类 skills 会描述如何测试或验证你的代码是否正常工作。它们通常会与 playwright、tmux 或其他外部验证工具配合使用。
在内部,验证类 skills 对 Claude 输出质量的可衡量影响最大。让一位工程师花一周时间,把你的验证类 skills 打磨到优秀水平,可能是很值得的。
可以考虑一些技巧,比如让 Claude 录制其输出的视频,这样你就能准确看到它测试了什么;或者在每一步对状态执行程序化断言。这些通常通过在 skill 中包含各种脚本来完成。
示例包括:
-
signup-flow-driver — 在无头浏览器中跑完整个 signup → email verify → onboarding 流程,并在每一步提供用于断言状态的 hooks
-
checkout-verifier — 使用 Stripe 测试卡驱动结账 UI,验证发票确实进入了正确状态
-
tmux-cli-driver — 用于交互式 CLI 测试,适合你要验证的对象需要 TTY 的情况
3. 数据获取与分析
这类 skills 会连接到你的数据和监控技术栈。这些 skills 可能包含用于带凭证获取数据的库、特定 dashboard id 等,也会包含常见工作流或获取数据方式的说明。
示例包括:
-
funnel-query — “我要 join 哪些事件,才能看到 signup → activation → paid”,以及真正存放规范 user_id 的那张表
-
cohort-compare — 比较两个 cohort 的留存率或转化率,标记具有统计显著性的差异,并链接到 segment 定义
-
grafana — datasource UID、集群名称、问题 → dashboard 查询表
-
datadog — 字段参考(@request_id 与 trace_id 的区别)、服务列表、指标前缀约定
4. 业务流程和团队自动化
这类 skills 会把重复性工作流自动化成一个命令。这些 skills 通常是相当简单的说明,但可能对其他 skills 或 MCPs 有更复杂的依赖。对这类 skills 来说,把之前的结果保存在日志文件中,可以帮助模型保持一致,并回顾工作流之前的执行情况。
示例包括:
-
standup-post — 汇总你的 ticket tracker、GitHub 活动和之前的 Slack → 格式化 standup,只包含变化部分
-
create--ticket — 强制执行 schema(有效的 enum 值、必填字段)以及创建后的工作流(ping reviewer、在 Slack 中链接)
-
weekly-recap — 已合并 PR + 已关闭工单 + deploys → 格式化的回顾帖子
5. 代码脚手架和模板
这类 skills 会为代码库中特定功能生成框架样板代码。你可以把这些 skills 与可组合的脚本结合使用。当你的脚手架包含无法完全由代码覆盖的自然语言需求时,它们尤其有用。
示例包括:
-
new--workflow — 用你的注解脚手架化创建新的服务/workflow/handler
-
new-migration — 你的 migration 文件模板以及常见 gotchas
-
create-app — 创建新的内部应用,并预先接好你的 auth、日志和 deploy 配置
6. 代码质量和 review
这类 skills 会在你的组织内部强制执行代码质量,并帮助 review 代码。为了获得最大健壮性,它们可以包含确定性的脚本或工具。你可能希望把这些 skills 作为 hooks 的一部分,或放进 GitHub Action 中自动运行。
-
adversarial-review — 启动一个带着新鲜视角的 subagent 来提出批评,实施修复并反复迭代,直到发现的问题退化成挑刺
-
code-style — 强制执行代码风格,尤其是 Claude 默认做得不好的那些风格。
-
testing-practices — 关于如何编写测试以及测试什么的说明。
7. CI/CD 与部署
这类 skills 可以帮助你在代码库中获取、推送和部署代码。这些 skills 可能会引用其他 skills 来收集数据。
示例包括:
-
babysit-pr — 监控一个 PR → 重试不稳定的 CI → 解决合并冲突 → 启用自动合并
-
deploy- — 构建 → smoke test → 渐进式流量 rollout,并比较错误率 → 出现回归时自动 rollback
-
cherry-pick-prod — 独立 worktree → cherry-pick → 冲突解决 → 带模板的 PR
8. Runbooks
这类 skills 会接收一个症状(比如 Slack thread、alert 或错误特征),完成一轮多工具调查,并生成结构化报告。
示例包括:
-
-debugging — 为你流量最高的服务建立“症状 → 工具 → 查询模式”的映射
-
oncall-runner — 拉取 alert → 检查常见问题源 → 格式化发现
-
log-correlator — 给定一个 request ID,从每一个可能处理过它的系统中拉取匹配日志
9. 基础设施运维
这类 skills 会执行日常维护和运维流程,其中一些涉及破坏性操作,因此适合配备 guardrails。它们让工程师在关键操作中更容易遵循最佳实践。
示例包括:
-
-orphans — 找出孤立的 pods/volumes → 发布到 Slack → 观察期 → 用户确认 → 级联清理
-
dependency-management — 你所在组织的依赖审批工作流
-
cost-investigation — “为什么我们的存储/出站流量账单突然飙升”,并包含具体的 buckets 和 query patterns
制作 skills 的建议
一旦你决定要做哪个 skill,该怎么写它?下面是 Claude Code 团队在制作 skills 时的一些最佳实践、技巧和窍门
不要陈述显而易见的事情

Claude 已经知道如何写代码,也能阅读你的代码库。一个只是复述 Claude 默认会做什么的 skill,只会增加上下文,却不会增加价值。如果你发布的 skill 主要关于知识,请聚焦于那些能把 Claude 推离其常规思考方式的信息。
frontend design skill 是一个很好的例子;它由 Anthropic 的一位工程师构建,通过与客户反复迭代来改进 Claude 的设计品味,避免 Inter 字体和紫色渐变这类经典套路。
构建 gotchas 章节
任何 skill 中信号密度最高的内容,都是 Gotchas 部分。这些部分应该来自 Claude 使用你的 skill 时经常遇到的失败点。理想情况下,你会随着时间推移持续更新你的 skill,把这些 gotchas 记录下来。
例如:
“subscriptions 表是 append-only 的。你要找的行是 version 最高的那一行,而不是 created_at 最新的那一行。”“这个字段在 API gateway 里叫 @request_id,在 billing service 里叫 trace_id。它们是同一个值。”“Staging 即使在 Stripe webhook 实际没有处理成功时也会返回 200。要检查 payment_events 才能看到真实状态。”
使用文件系统和渐进式披露
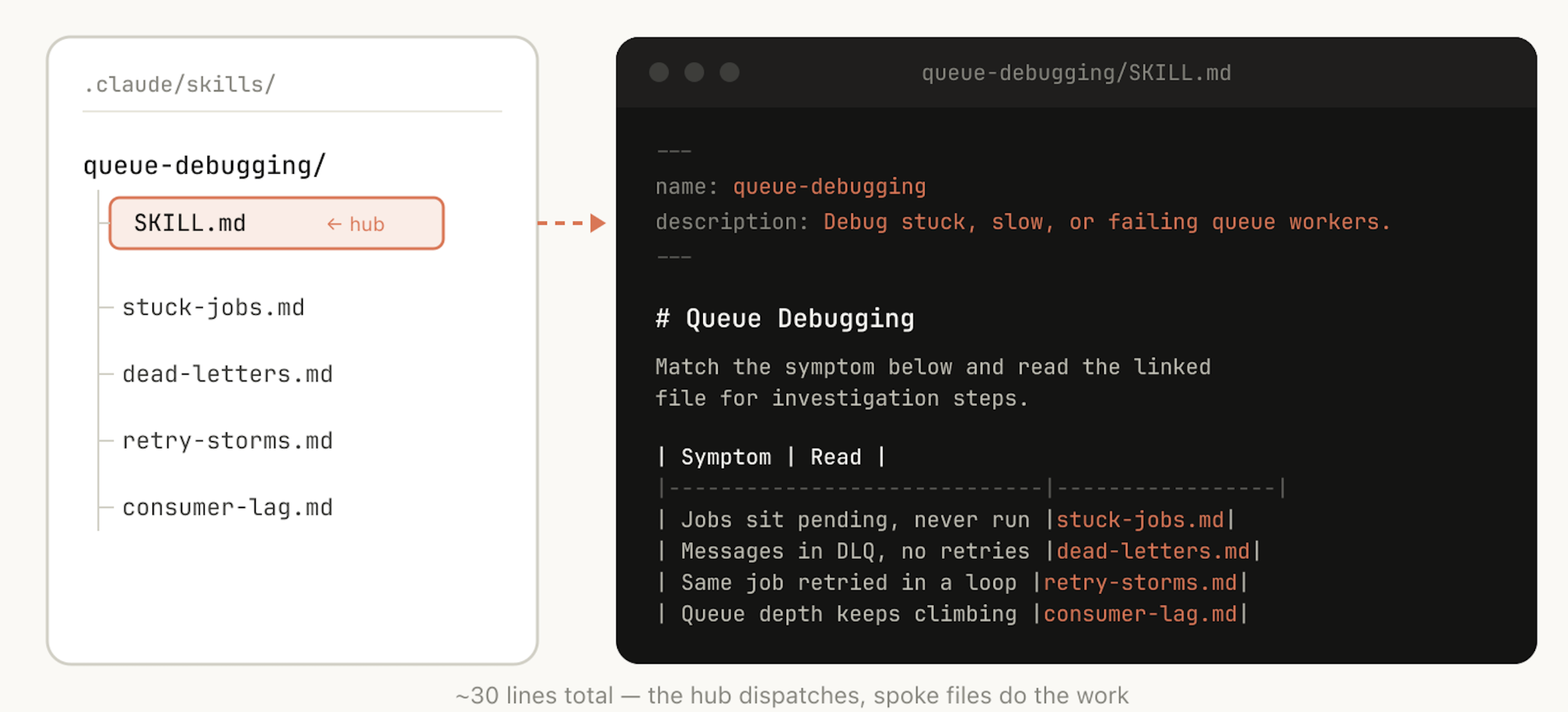
SKILL.md 文件指向几个 Claude 可以在特定场景下参考的其他文件。例如,如果某个 job 处于 pending 状态,它应该参考 stuck-jobs.md。
就像我们前面说的,skill 是一个文件夹,而不只是一个 Markdown 文件。你应该把整个文件系统都看作一种 context engineering 和 progressive disclosure。告诉 Claude 你的 skill 里有哪些文件,它会在合适的时候读取它们。
最简单的渐进式披露形式,就是指向其他 Markdown 文件供 Claude 使用。例如,你可以把详细的函数签名和用法示例拆到 references/api.md 中。
再举一个例子:如果你的最终输出是一个 markdown 文件,可以在 assets/ 中放一个模板文件,供复制和使用。
你可以放 references、scripts、examples 等文件夹,帮助 Claude 更有效地工作。
避免把 Claude 强行带上固定轨道
Claude 通常会尽量遵循你的指令,而且因为 skills 复用性很强,你需要注意不要把指令写得过于具体。给 Claude 必要的信息,但也要给它根据具体情况调整的灵活性。
例如:
想清楚设置流程
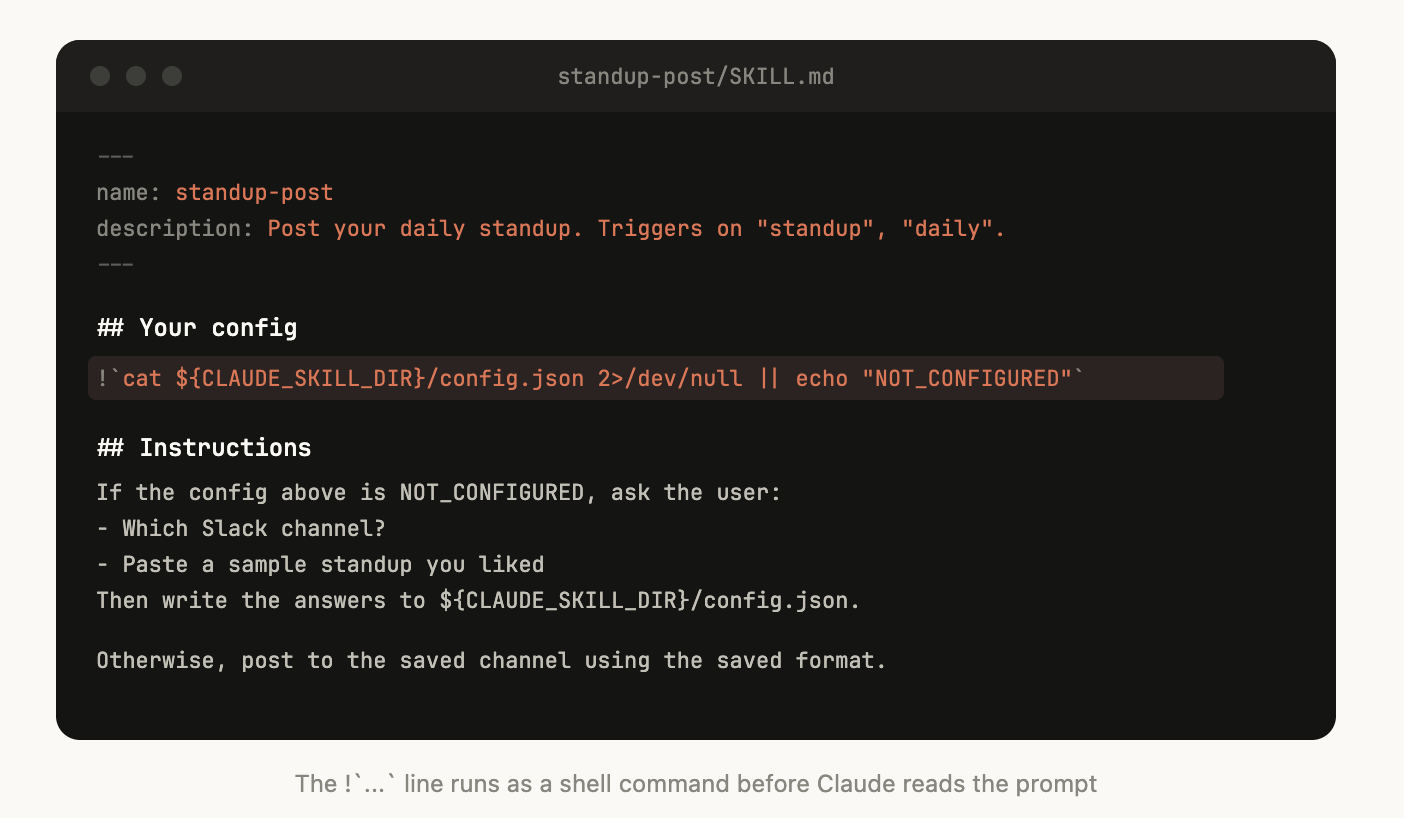
上面的 skill 会在配置中没有包含 Slack channel 时,提示用户输入。
有些 skills 可能需要结合用户提供的上下文来设置。例如,如果你正在制作一个把你的 standup 发布到 Slack 的 skill,你可能希望 Claude 询问应该发布到哪个 Slack channel。
一个好的模式,是像上面的例子那样,把这些设置信息存放在 skill 目录中的 config.json 文件里。如果 config 尚未设置好,Agent 就可以向用户询问信息。
如果你希望 Agent 提出结构化的多选问题,可以指示 Claude 使用 AskUserQuestion 工具。
为模型写 descriptions,而不是为人类写
当 Claude Code 启动一个会话时,它会构建一份所有可用 skills 及其描述的列表。Claude 会扫描这份列表来判断“这个请求有没有对应的 skill?”这意味着 description 字段不是摘要,而是说明何时触发这个 skill。

在 skill 的描述中加入触发词很有帮助,比如“babysit”。
帮 Claude 记住
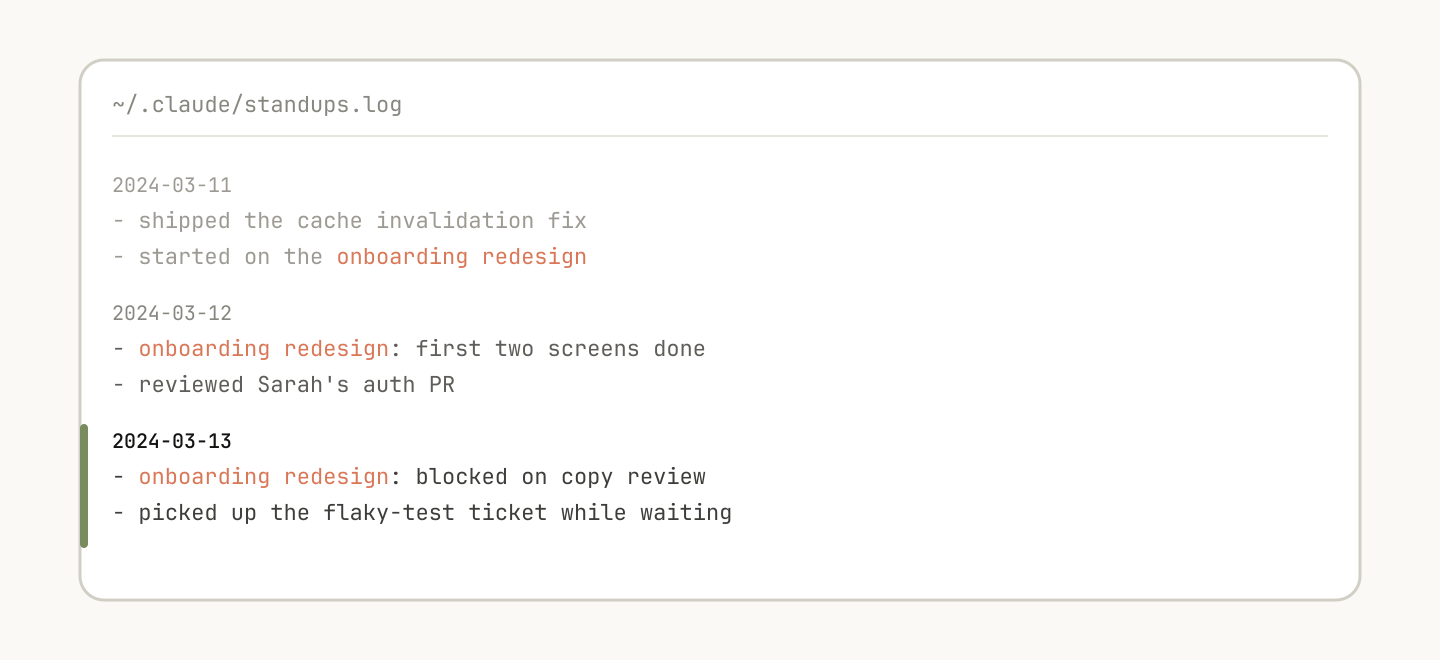
这个文本日志文件可以帮助 Claude 记住过去发生的事件,比如 review Sarah 的 auth PR。
有些 skills 可以通过在其中存储数据来包含某种形式的记忆。你可以把数据存到很简单的 append-only 文本日志文件或 JSON 文件里,也可以复杂到使用 SQLite 数据库。
例如,一个 standup-post skill 可能会维护一份 standups.log,记录它写过的每一篇帖子。这意味着下次你运行它时,Claude 会读取自己的历史,并能判断相比昨天发生了什么变化。
你可以使用环境变量 ${CLAUDE_PLUGIN_DATA} 获取一个稳定目录,用来存储数据;关于在 skills 中持久化数据,可以在这里阅读更多内容:https://code.claude.com/docs/en/plugins-reference#persistent-data-directory。
存储脚本并生成代码
你能给 Claude 的最强大工具之一就是代码。给 Claude 提供脚本和库,可以让 Claude 把回合用在组合上,决定下一步要做什么,而不是重新构建样板代码。
例如,在你的 data-science skill 中,你可能会有一个函数库,用来从事件源获取数据。为了让 Claude 做复杂分析,你可以给它一组这样的辅助函数:
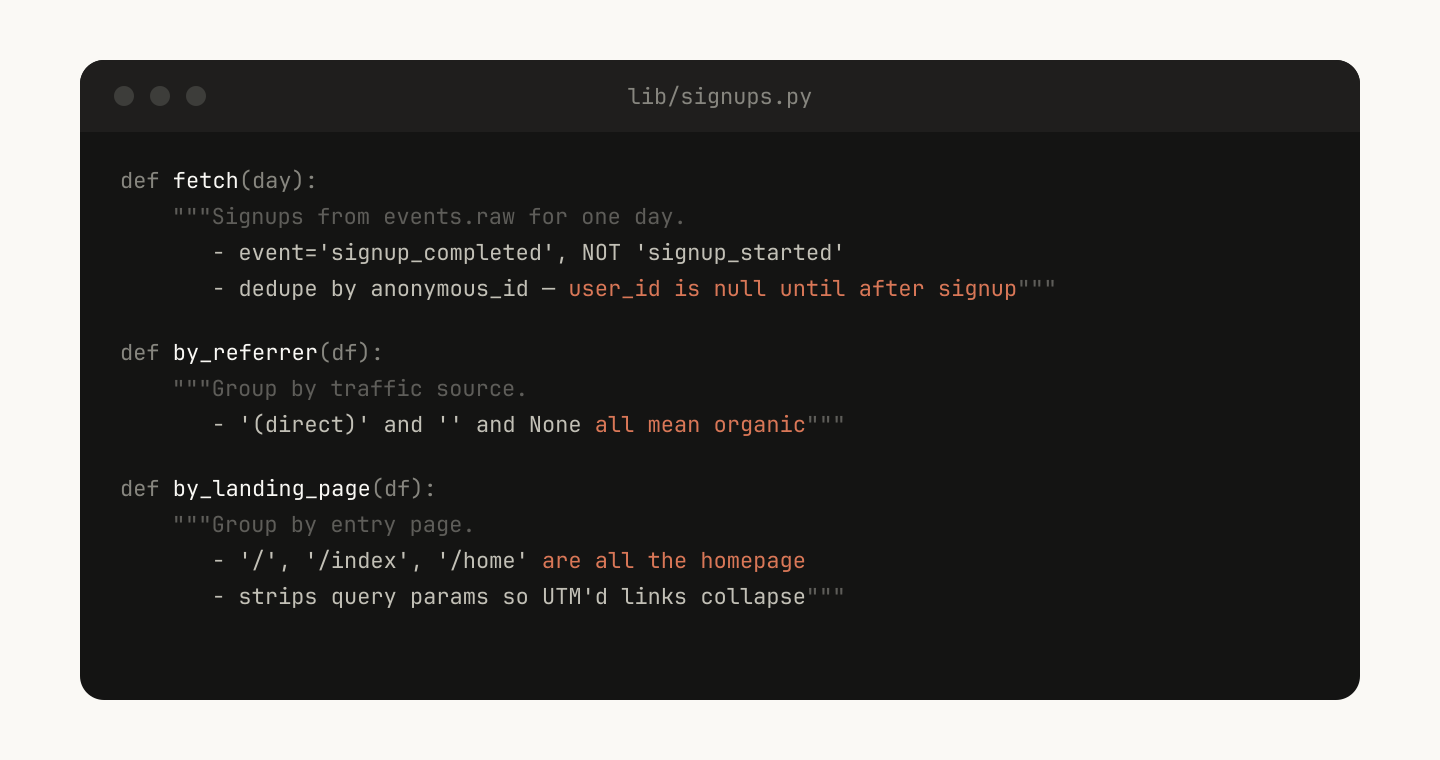
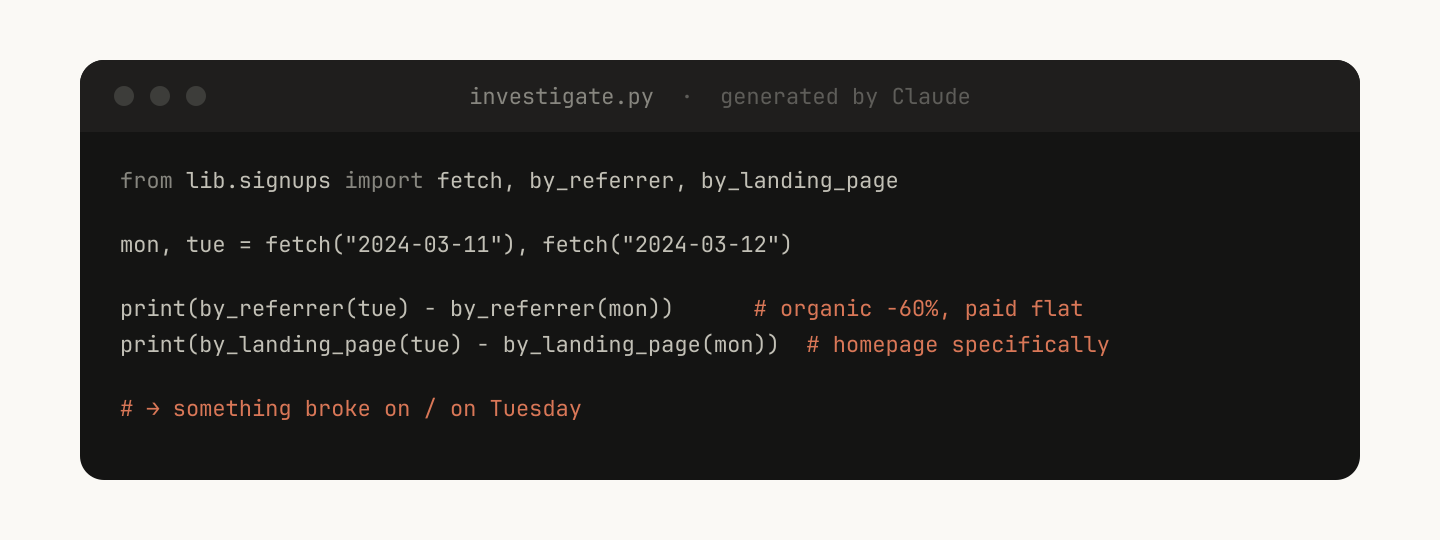
Claude 随后可以即时生成脚本,把这些功能组合起来,对类似“周二发生了什么?”这样的 prompts 做更高级的分析。
使用按需 hooks
Skills 可以包含 hooks,这些 hooks 只会在该 skill 被调用时激活,并且只在 session 持续期间有效。对于那些你不想一直运行、但有时非常有用的更有主张的 hooks,可以使用这种方式。
例如:
-
/careful — 通过 Bash 上的 PreToolUse matcher 阻止 rm -rf、DROP TABLE、force-push、kubectl delete。只有当你知道自己正在接触生产环境时,才会想启用它;如果它一直开启,会把你逼疯。
-
/freeze — 阻止任何不在特定目录中的 Edit/Write。调试时很有用:“我想加日志,但总是不小心‘修复’了无关代码。”
分发 skills
Skills 的最大好处之一,是你可以把它们分享给团队里的其他人。
你可能会用两种方式与他人共享 skills:
-
把你的 skills 提交到你的 repo 中(放在 ./.claude/skills 下)
-
制作一个插件,并建立一个 Claude Code Plugin marketplace,让用户可以上传和安装插件(更多信息请阅读这里的文档)
对于跨相对少量 repo 协作的小团队,把 skills check in 到 repo 里效果很好。但每个被 check in 的 skill 也都会给模型的上下文增加一点负担。随着规模扩大,一个内部插件 marketplace 可以让你分发 skills,让团队自行决定安装哪些 skills,并包含 setup flow。
管理 skills marketplace
你如何决定哪些 skills 应该进入 marketplace?人们该如何提交它们?
在 Anthropic,我们没有一个集中式团队来做决定;相反,我们会尝试以自然方式找出最有用的 skills。如果有人有一个 skill 想让大家试用,他们可以把它上传到 GitHub 中的 sandbox 文件夹,然后在 Slack 或其他论坛里把链接发给大家。
一旦某个 skill 获得了 traction(这由 skill owner 来决定),他们就可以提交 PR,把它移入 marketplace。
组合使用 skills
你可能会希望 skills 之间存在依赖关系。例如,你可能有一个 file upload skill 用来上传文件,还有一个 CSV generation skill 用来生成 CSV 并上传它。这类依赖管理目前还没有原生内置到 marketplaces 或 skills 中,但你可以直接按名称引用其他 skills,如果它们已经安装,模型就会调用它们。
衡量 skills
为了了解一个 skill 的表现,我们使用一个 PreToolUse hook,在公司内部记录 skill 使用情况(示例代码在这里)。这意味着我们可以找到那些热门的 skills,或是相比预期触发不足的 skills。
开始使用
Skills 的最佳实践仍在演进。我们大多数最好的 skills 一开始都只有几行文字和一个 gotcha,后来之所以变得更好,是因为当 Claude 遇到新的 edge cases 时,人们会持续往里面补充内容。
理解 skills 的最好方式,就是开始使用、做实验,并看看什么适合你。
本文作者是 Anthropic 技术团队成员 Thariq Shihipar,他负责 Claude Code 相关工作。





